Laser physicists of the attoworld team at Ludwig Maximilians Universität, the Max Planck Institute of Quantum Optics and the Center for Molecular Fingerprinting have achieved unprecedented control over light pulses in the mid-infrared wavelength range.
Ultrashort infrared light pulses are the key to a wide range of technological applications. The oscillating infrared light field can excite molecules in a sample to vibrate at specific frequencies, or drive ultrafast electric currents in semiconductors. Physicists from the attoworld team at the Ludwig-Maximilians-Universität München (LMU), the Max Planck Institute of Quantum Optics (MPQ) and the Hungarian Center for Molecular Fingerprinting (CMF) have now succeeded in generating ultrashort mid-infrared pulses and precisely controlling their electric-field waveforms. The basis for the new mid-infrared source is a stabilized laser system that generates light pulses with a precisely defined waveform at near-infrared wavelengths. The pulses consist of only one oscillation of the light wave and are thus only a few femtoseconds long (a femtosecond being one millionth of a billionth of a second, 10-15 s). The team utilizes frequency-mixing processes in nonlinear crystals to translate the near-infrared pulses into controllable infrared waveforms. With this infrared waveform manipulator at hand, new possibilities of optical control for biomedical applications and quantum electronics come into reach.
Anyone intending to exploit the oscillating waveform of ultrashort light pulses, to drive cutting-edge electro-optical processes for example, faces the same question — how to best control the waveform themselves. The generation of ultrashort pulses with adjustable waveforms has been demonstrated in different wavelength ranges like the UV-visible and the near-infrared. While ultrashort-pulse manipulation in the mid-infrared has enormous potential for new applications, its realization, turned out to be particularly challenging, as concepts from other wavelength ranges cannot be readily adopted. Laser physicists from the attoworld team at the Ludwig Maximilian University, the Max Planck Institute of Quantum Optics and the Hungarian Center for Molecular Fingerprinting have taken on this challenge, and have now succeeded in developing a technology that enables the control of the waveform — and thus the electric field underlying the ultrashort laser pulses — in the mid-infrared range. To do this, they first created a new laser platform that provides highly reproducible light pulses in the adjacent near-infrared spectral range with wavelengths spanning from 1 to 3 micrometres and pulse durations of merely a few femtoseconds.
When these pulses are sent into a suitable nonlinear crystal, the generation of long-wavelength infrared pulses can be induced by taking advantage of complex frequency-mixing processes. In this way, the team succeeded in producing light pulses with an exceptionally large spectral coverage of more than three optical octaves, from 1 to 12 micrometres. The researchers were not only able to understand and simulate the underlying physics of the mixing processes, but also developed a new approach to precisely control the oscillations of the generated mid-infrared light via the tuning of the laser input parameters.
The resulting adjustable waveforms can, for example, selectively trigger certain electronic processes in solids, which could allow to achieve much higher electronic signal processing speeds in future. "On this basis, one could envision the development of light-controlled electronics. If opto-electronic devices were to operate at frequencies of the generated light, you could speed up today's electronics by at least a factor of 1000," explains Dr. Philipp Steinleitner, one of the three lead authors of the study.
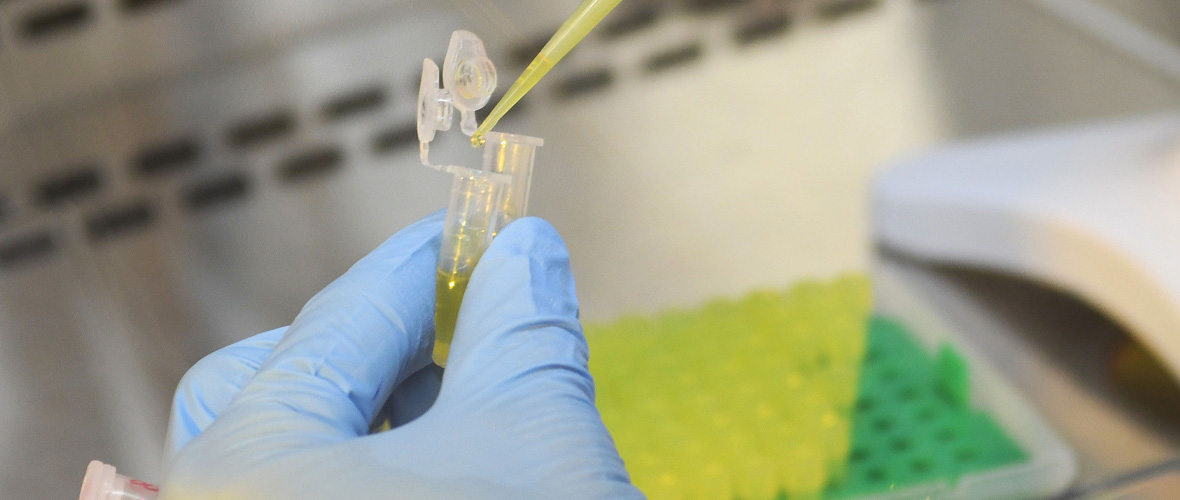
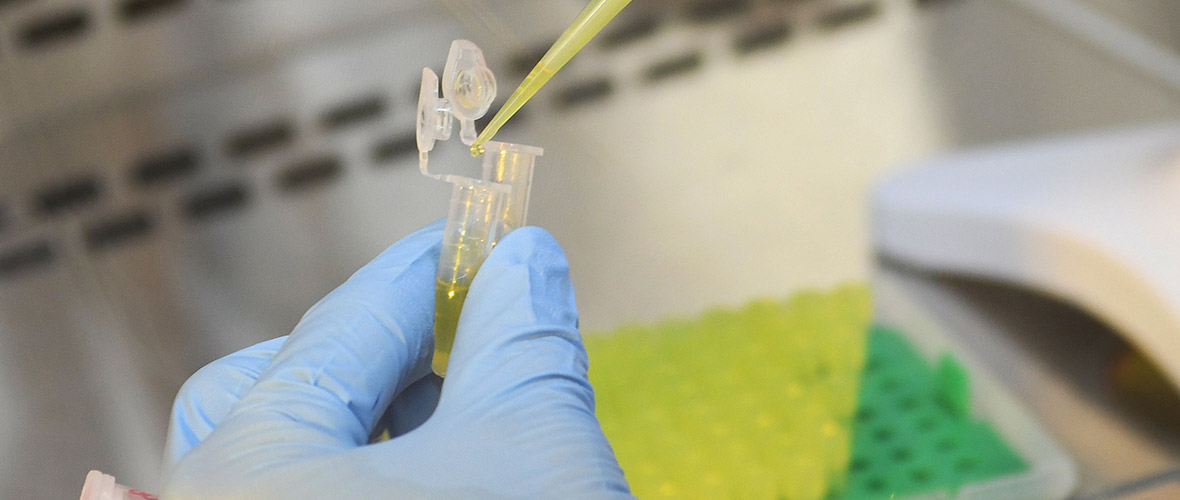
The attoworld physicists are paying particular attention to the use of the new light technology for the spectroscopy of molecules. When mid-infrared light passes through a sample liquid, for example human blood, molecules in the sample begin to oscillate and in turn emit characteristic light waves. Detecting the molecular response provides a unique fingerprint that depends on the exact composition of the sample. "With our laser technology, we have significantly expanded the controllable wavelength range in the infrared," explains Dr. Nathalie Nagl, also first author of the study. "The additional wavelengths give us the opportunity to analyze even more precisely how a mixture of molecules is composed," she continues.
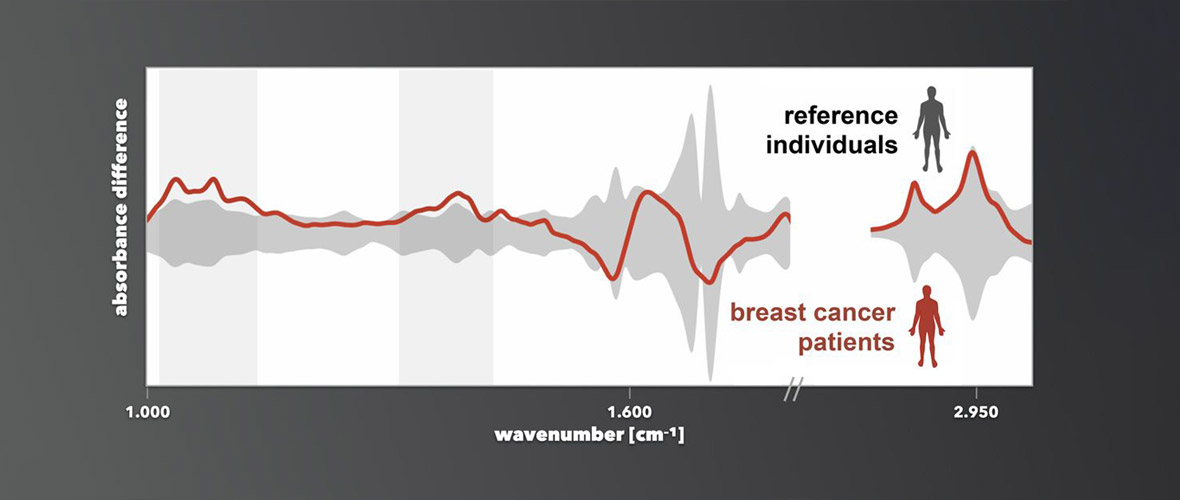
In the attoworld group, colleagues from the Broadband Infrared Diagnostics (BIRD) team led by Dr. Mihaela Zigman and the CMF Research team led by Dr. Alexander Weigel are particularly interested in measuring the precise infrared molecular fingerprints of human blood samples. The vision is to identify characteristic signatures that allow to diagnose diseases like cancer. A developing tumor, for example, leads to small and highly complex changes in the molecular composition of the blood. The goal is to detect these changes, and to enable the early diagnosis of serious diseases by measuring the infrared fingerprint of a simple drop of human blood.
"In the future, our laser technology will allow our colleagues to detect previously undetectable changes in specific biomolecules such as proteins or lipids. It thus increases the reliability of future medical diagnostics using infrared laser technology," explains Dr. Maciej Kowalczyk, also first author of the study.
Picture description:
Ultrashort laser pulses are sent into a nonlinear crystal and undergo complex frequency-mixing processes. By adjusting the laser input parameters, the scientists were able to precisely control the oscillations of the generated mid-infrared light.
Illustration: Dennis Luck, Alexander Gelin
Original publication:
Philipp Steinleitner, Nathalie Nagl, Maciej Kowalczyk, Jinwei Zhang, Vladimir Pervak, Christina Hofer, Arkadiusz Hudzikowski, Jarosław Sotor, Alexander Weigel, Ferenc Krausz, Ka Fai Mak
Single-cycle infrared waveform control
Nature photonics, 26. May 2022
DOI: 10.1038/s41566-022-01001-2
More information:
Dr. Nathalie Nagl
Ludwig-Maximilians-Universität München,Lehrstuhl für Experimentalphysik – Laserphysik
Max Planck Institute of Quantum Optics
Am Coulombwall 1, 85748 Garching, Germany
Tel: +49.89.289 53280
Dr. Maciej Kowalczyk
Ludwig-Maximilians-Universität München
Chair for Experimental Physics — Laserphysics
Center for Molecular Fingerprinting
Am Coulombwall 1, 85748 Garching, Germany
Tel.: Tel: +49.89.289 54012
Internet: www.attoworld.de/bird, www.attoworld.de/bird, www.mukkozpont.hu